
« On va tout réécrire from scratch. »
C'est souvent la première réaction face à une application legacy qui freine la croissance. Le code a dix ans, personne ne comprend certains modules, chaque évolution prend trois fois plus de temps qu'elle ne devrait — et la tentation du « big bang » est forte. On arrête tout, on reconstruit à neuf, on migre en une fois.
Dans la réalité, cette approche échoue dans la majorité des cas. Dépassement de budget, périmètre qui dérive, migration de données qui ne se passe pas comme prévu, et un système legacy qu'il faut maintenir en parallèle pendant des mois — parfois des années — de plus que prévu.
Il existe une alternative : le strangler fig pattern. Un modèle de migration progressive, éprouvé en production, qui permet de remplacer un système legacy sans jamais l'arrêter. Cet article explique le principe, les étapes concrètes et les pièges à éviter.
Qu'est-ce que le strangler fig pattern ?
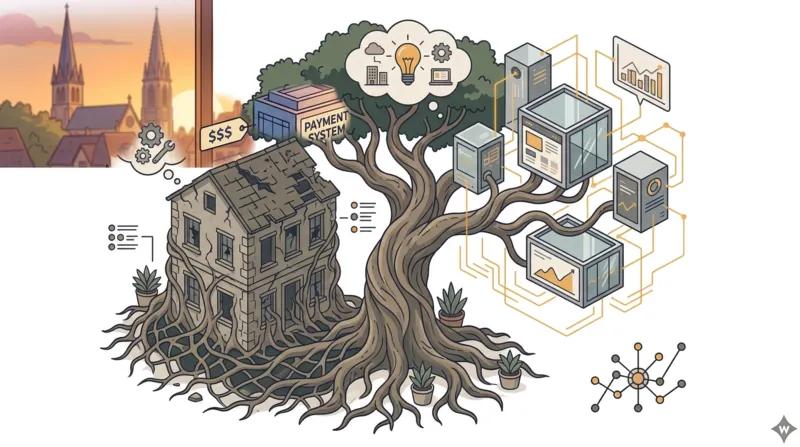
Le nom vient d'une observation de Martin Fowler dans les forêts tropicales. Le figuier étrangleur (strangler fig) est un arbre parasite qui germe sur un arbre hôte, développe progressivement ses racines autour du tronc, puis finit par le remplacer entièrement. L'arbre hôte disparaît — mais à aucun moment il n'y a de vide.
Transposé au logiciel, le principe est le même : on construit le nouveau système autour de l'ancien, module par module, en routant progressivement le trafic vers les nouveaux composants. Quand tous les flux passent par le nouveau système, l'ancien est décommissionné.
Le schéma mental en trois temps
- Intercepter — poser une couche de routage (proxy, API gateway, reverse proxy) devant le legacy pour contrôler le flux.
- Migrer — réécrire les modules un par un dans le nouveau système, derrière cette même couche de routage.
- Couper — une fois qu'un module est entièrement migré et validé, retirer la version legacy.
À chaque étape, le système reste fonctionnel. Les utilisateurs ne voient aucune interruption. Et chaque module migré apporte de la valeur immédiatement, sans attendre que l'ensemble soit terminé.
Big bang vs migration progressive
Le big bang est séduisant sur un slide de comité de direction. « Dans 8 mois, on aura un système neuf. » En pratique, les 8 mois deviennent 18, le budget double et le legacy continue de tourner en parallèle parce que la migration n'est jamais vraiment « finie ».
Quand le big bang reste pertinent
Le big bang n'est pas toujours irrationnel. Il peut se justifier dans quelques cas précis :
- Le système est très petit — quelques milliers de lignes, un périmètre fonctionnel limité, pas de données critiques à migrer.
- Le legacy est irrécupérable — aucune API, aucun point d'entrée exploitable, pas de documentation, pas de tests. Le coût de la couche de routage dépasse celui de la réécriture.
- Le business accepte une fenêtre d'arrêt — l'application n'est pas critique et peut être indisponible quelques jours sans impact majeur.
En dehors de ces cas, la migration progressive est presque toujours le choix le plus rationnel.
Les étapes concrètes d'une migration strangler fig
Étape 1 — Cartographier le legacy
Avant de migrer quoi que ce soit, il faut comprendre ce qui existe. C'est la phase la plus souvent négligée — et celle qui conditionne tout le reste.
Un audit technique du système en place permet d'identifier :
- Les modules fonctionnels — quelles fonctions métier sont couvertes, par quels composants, avec quelles dépendances entre eux.
- Les flux de données — quelles bases, quelles API, quels échanges entre systèmes. C'est souvent là que se cachent les couplages les plus vicieux.
- Les zones de risque — le code que personne ne touche « parce que ça marche », les modules sans tests, les fonctions critiques pour le business mais fragiles techniquement.
- La connaissance métier embarquée — les règles de gestion codées en dur, parfois non documentées, que seul le code source peut révéler.
Cette cartographie n'a pas besoin d'être exhaustive au départ. Elle doit être suffisamment précise pour prioriser les modules à migrer et identifier les dépendances bloquantes.
Étape 2 — Poser la couche de routage
C'est la fondation technique du strangler fig. On place un composant — reverse proxy, API gateway, middleware applicatif — entre les utilisateurs et le système. Ce composant décide, pour chaque requête, si elle doit être routée vers le legacy ou vers le nouveau système.
En pratique, les implémentations courantes sont :
- Reverse proxy (Nginx, Traefik, HAProxy) — routage par URL. Simple, performant, adapté quand le legacy et le nouveau système ont des chemins d'URL distincts.
- API gateway — routage par endpoint. Idéal pour les architectures orientées API où chaque service expose des endpoints indépendants.
- Middleware applicatif — routage dans le code. Plus souple mais plus intrusif. Utile quand le legacy est un monolithe dont on ne peut pas séparer les URL proprement.
Le choix dépend de l'architecture existante. L'important est que cette couche soit transparente pour les utilisateurs et réversible — on doit pouvoir basculer le trafic dans un sens ou dans l'autre sans risque.
Étape 3 — Migrer par tranches fonctionnelles
C'est le cœur du pattern. On ne migre pas « la couche de données » ou « le frontend » — on migre des tranches fonctionnelles complètes : un module métier de bout en bout, avec son interface, sa logique et ses données.
Chaque tranche suit le même cycle :
- Réécrire le module dans le nouveau système.
- Tester la parité — vérifier que le nouveau module reproduit exactement le comportement de l'ancien (mêmes entrées → mêmes sorties).
- Basculer le trafic — router progressivement les requêtes vers le nouveau module (canary release, feature flags, pourcentage de trafic).
- Valider en production — surveiller les métriques, les logs, les retours utilisateurs.
- Couper l'ancien — une fois la confiance établie, retirer le module legacy.
Étape 4 — Gérer la cohabitation
Pendant la migration, deux systèmes coexistent. C'est la phase la plus délicate — et la plus coûteuse si elle est mal gérée.
Les points d'attention :
- Synchronisation des données — si le legacy et le nouveau système partagent une base de données, les schémas doivent rester compatibles. Si les bases sont distinctes, un mécanisme de synchronisation (event sourcing, CDC, ETL) est nécessaire.
- Sessions et authentification — les utilisateurs ne doivent pas se reconnecter quand ils passent d'un module legacy à un module migré. Un SSO ou un token partagé résout ce problème.
- Cohérence UX — si l'interface change progressivement, il faut que la transition soit naturelle. Un changement trop brutal entre deux modules crée de la confusion.
Étape 5 — Décommissionner le legacy
C'est l'étape que tout le monde oublie. Une fois qu'un module est migré et validé en production, il faut activement retirer la version legacy. Sinon, le vieux code reste dans le dépôt, la vieille infrastructure continue de tourner et le coût de maintenance ne baisse jamais.
Le décommissionnement inclut : supprimer le code legacy, éteindre les services associés, révoquer les accès, et mettre à jour la documentation. Chaque module décommissionné est une victoire concrète qui réduit le périmètre de dette technique et simplifie l'ensemble.
Prioriser les modules à migrer
Tout ne peut pas être migré en même temps. Il faut choisir par quoi commencer — et ce choix est stratégique.
La matrice valeur × complexité
Un outil simple et efficace : croiser la valeur métier du module (impact sur le business, fréquence d'utilisation, revenus générés) avec sa complexité de migration (couplage avec d'autres modules, volume de données, règles métier implicites).
Commencer par les modules découplés
Indépendamment de la valeur métier, le premier module migré devrait être le plus indépendant possible. Un module faiblement couplé au reste du système se migre sans effet de bord — et sert de preuve de concept pour valider l'approche, la couche de routage et les processus de test.
Les bons candidats : un module de reporting, une page publique, un outil interne peu critique. Le but n'est pas de commencer par le plus important, mais par celui qui permettra d'apprendre vite et de gagner la confiance de l'équipe et du management.
Les pièges courants
Le big bang déguisé
Le piège le plus fréquent : commencer par le strangler fig, puis glisser progressivement vers un big bang. « On va migrer les 4 modules en parallèle pour aller plus vite. » « On ne peut pas livrer le module A sans le module B. » « Finalement on refait tout le frontend d'un coup. »
Chaque fois que le périmètre d'une tranche de migration s'élargit, on perd les bénéfices du pattern. La discipline consiste à garder des tranches petites, indépendantes et livrables.
Négliger la cartographie
Migrer sans avoir cartographié le legacy, c'est opérer à l'aveugle. Les couplages cachés entre modules ne se révèlent qu'au moment de la bascule — et à ce stade, le retour en arrière est coûteux.
Un cahier des charges de migration, même léger, réduit considérablement les surprises.
Sous-estimer la cohabitation
La double maintenance (legacy + nouveau système) a un coût réel. Chaque jour où les deux coexistent, chaque bug à corriger dans les deux versions, chaque fonctionnalité à implémenter en double consomme de la bande passante. Ce coût de refonte doit être budgété et planifié dès le départ.
Oublier de couper l'ancien
C'est le piège le plus insidieux. Le nouveau module fonctionne, le trafic est basculé… mais personne ne retire le legacy. Les serveurs tournent encore, le code est toujours dans le dépôt, et six mois plus tard, quelqu'un y fait une correction « en urgence » parce que « c'est plus rapide ».
Le décommissionnement doit être un critère de done au même titre que le développement et les tests. Un module n'est pas migré tant que l'ancien n'est pas éteint.
Indicateurs de succès
Comment savoir si la migration avance dans la bonne direction ? Trois familles de métriques à suivre.
- Couverture migrée — pourcentage du trafic (ou des fonctionnalités, ou des endpoints) passant par le nouveau système. C'est l'indicateur principal d'avancement.
- Incidents post-bascule — nombre de bugs ou régressions constatés après chaque migration de module. S'il augmente, les tests de parité sont insuffisants.
- Vélocité de développement — le temps moyen pour livrer une fonctionnalité sur le nouveau système vs sur le legacy. Si la vélocité ne s'améliore pas, la migration n'apporte pas les gains attendus.
Conclusion
La migration progressive n'est pas plus lente que le big bang. Elle est plus sûre, plus prévisible et plus rentable. Chaque module migré apporte de la valeur immédiatement, réduit le risque global et simplifie le système existant.
Le strangler fig pattern n'est pas une méthode théorique. C'est une approche éprouvée sur des systèmes de toutes tailles, de la PME industrielle au grand groupe. Le principe est toujours le même : ne jamais arrêter le système en place, construire autour, et retirer l'ancien quand le nouveau a fait ses preuves.
Migrer un legacy, ce n'est pas démolir une maison pour en reconstruire une. C'est remplacer chaque pièce, une par une, sans que les habitants quittent les lieux.
Message clé
Une refonte big bang, c'est un pari. Une migration strangler fig, c'est un plan.
Votre application legacy freine votre activité et vous envisagez une refonte ? Parlons-en — je vous aiderai à définir la stratégie de migration la plus adaptée à votre contexte.